「DBひとりでできるもん」運営チーム
「DBひとりでできるもん」運営チーム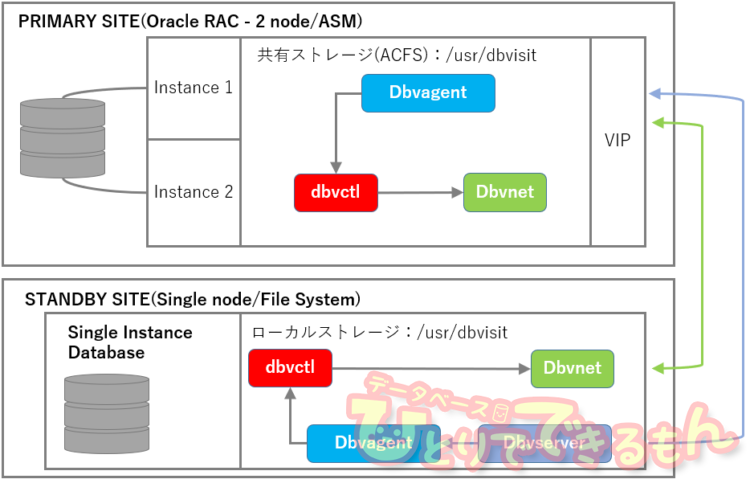
目次
- はじめに
- 構成図
- 検証開始
- node1でクラスタリソースの状態を確認します。
- node1をシャットダウンします。
- node2でクラスタリソースの状態を確認します。
- ログ適用の確認の為、ログスイッチを行います。
- Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
- Dbvisit Standbyのデーモンが、ログ適用を実施するのを待ちます。
- Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
- 切り替え後、自動でログ適用が行われる所まで、確認できたので
- ノード起動後、クラスタウェアリソースの状態を確認します。
- ログ適用確認の為、ログスイッチを行います。
- Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
- Dbvisit Standbyのデーモンがログ適用を実施するのを待ちます。
- Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
- 今回のまとめ
- 最後に
はじめに
みなさん、こんにちは。
Dbvisit Standby製品チームです。
今日は前回の、第1弾:Dbvisit Standby構成例のご紹介(RAC to Single)に引き続き、
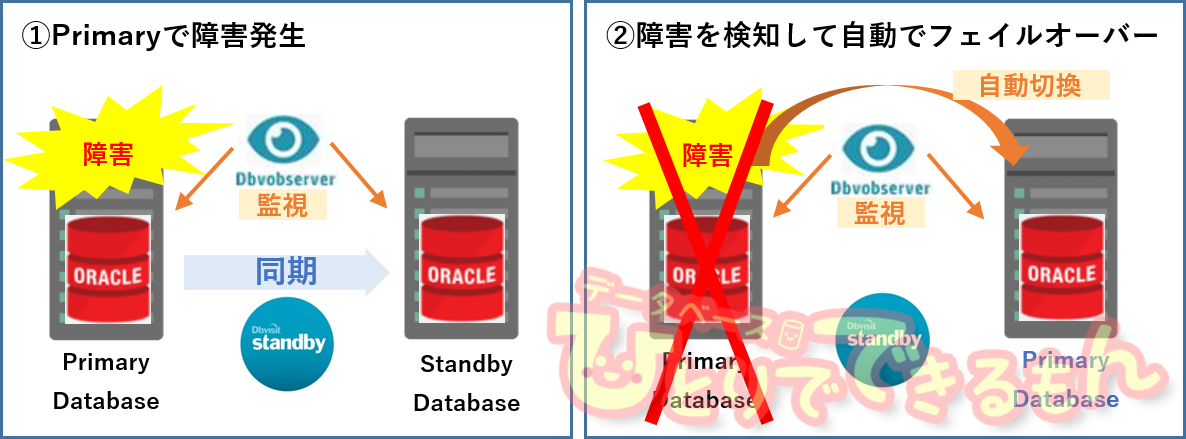
RACノード障害時の動きについて
についてご紹介させて頂きたいと思います。
よろしくお願いします!
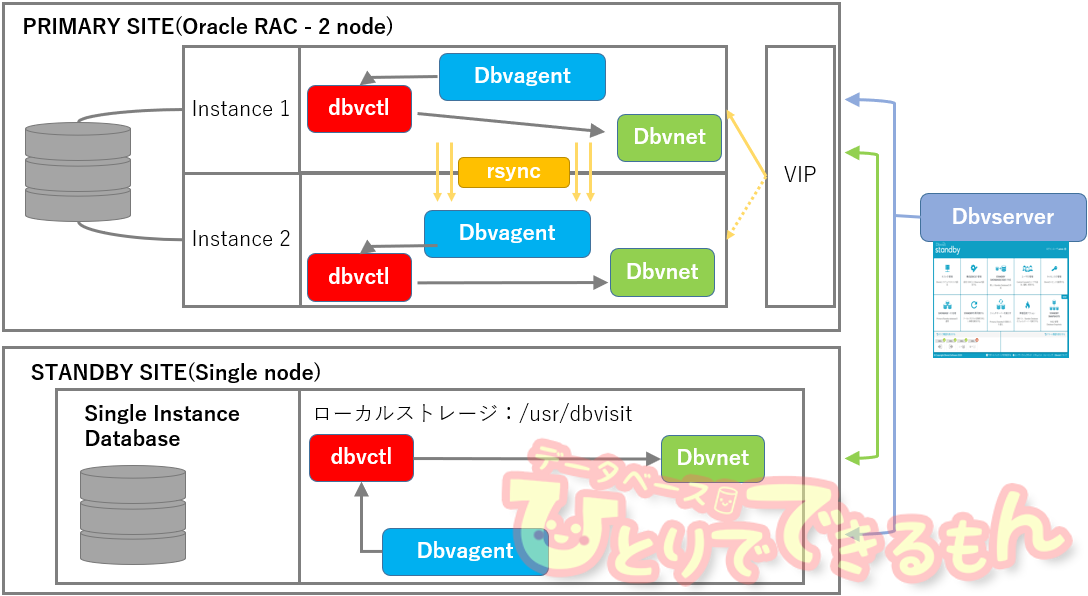
構成図
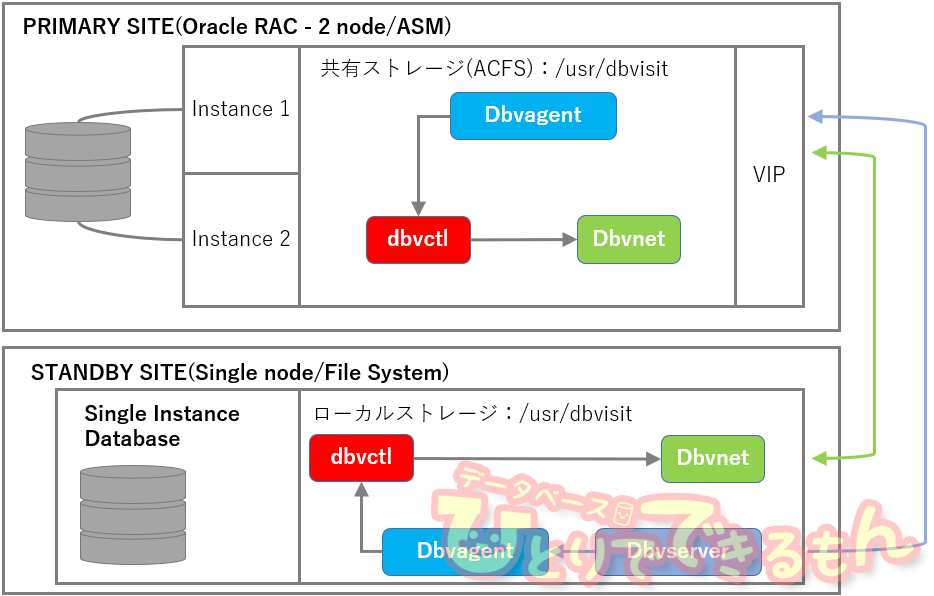
検証時の製品情報
| PRIMARY SITE | |
| OS | Red Hat Enterprise Linux 7.6 |
| DB | Oracle Database 11gR2 Standard Edition 2node RAC |
| ストレージ・タイプ | Oracle ASM |
| 共有ストレージ | Oracle ACFS |
| Dbvisit Standby | version 9.0 |
| STANDBY SITE | |
| OS | Red Hat Enterprise Linux 7.6 |
| DB | Oracle Database 11gR2 Standard Edition |
| ストレージ・タイプ | ファイルシステム |
| Dbvisit Standby | version 9.0 |
構成例について確認されたい方は、第1弾:Dbvisit Standby構成例のご紹介(RAC to Single)を、
ご参照ください。
Dbvisit Standbyの各コンポーネントについては、
【入門編】Dbvisit Standby 製品紹介 + アーキテクチャについてを参照ください。
本記事では、Dbvisit Standbyへの理解を深めることを目的としており
皆様の環境での動作を保証するものではありません。

検証開始
それではさっそく検証していきます。
今回の検証の確認ポイントは、以下の3つになります。
RAC ノード障害時、Dbvisit Standbyが別ノードで起動されること。
切り替え後、ログ適用が自動で行われること。
RAC ノード障害復旧時、障害発生前の状態に戻ること。
node1でクラスタリソースの状態を確認します。
$ crsctl stat res -t
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
dbvagent
1 ONLINE ONLINE node1
dbvnet
1 ONLINE ONLINE node1
※表示の都合上、Dbvisit Standby関連のリソースのみ抜粋しております。
node1をシャットダウンします。
# shutdown -h now
node2でクラスタリソースの状態を確認します。
$ crsctl stat res -t
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
Cluster Resources
--------------------------------------------------------------------------------
dbvagent
1 ONLINE ONLINE node2
dbvnet
1 ONLINE ONLINE node2
※表示の都合上、Dbvisit Standby関連のリソースのみ抜粋しております。
dbvnet、dbvagentがnode2で起動していることが確認できます。
これで確認ポイントの1つ目である、
「 RAC ノード障害時、Dbvisit Standbyが別ノードで起動されること」が確認できました!
ログ適用の確認の為、ログスイッチを行います。
SQL> select instance_name, status from gv$instance; INSTANCE_NAME STATUS -------------- ------- ORCL2 OPEN SQL> alter system switch logfile; システムが変更されました。 SQL> alter system switch logfile; システムが変更されました。 SQL> alter system switch logfile; システムが変更されました。 SQL> exit
Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
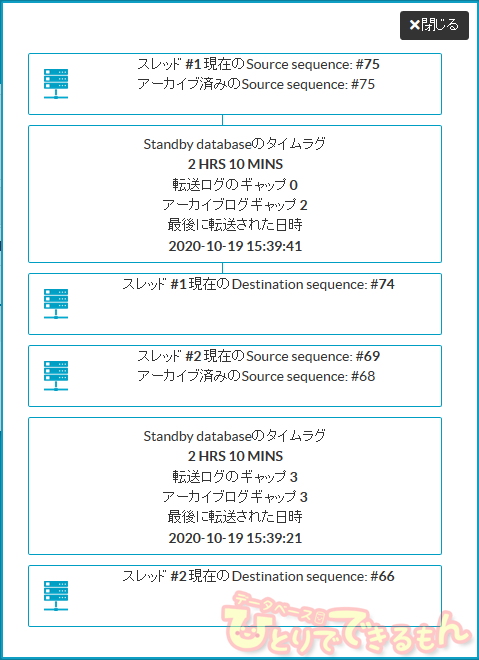
Dbvisit Standbyのデーモンが、ログ適用を実施するのを待ちます。
Tips:Dbvisit Standbyでは、様々なパラメータを設定し、ログ転送・適用の間隔を
スケジューリング可能となっております。
例:DMN_DBVISIT_INTERVAL・DMN_MONITOR_INTERVAL等
その他のパラメータや詳細等は、Dbvisit Standby User Guideを参照ください。
Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。

ログギャップがなくなり、ログが適用されたことが確認できます。
こちらで確認ポイントの2つ目である、「切り替え後ログ適用が自動で行われること」が、
確認できました!
切り替え後、自動でログ適用が行われる所まで、確認できたので
続いて、 RAC ノード障害復旧時にDbvisit Standbyが元のノードで戻るのかを
試していきたいと思います。まず、先程シャットダウンしたノードを起動させます。
ノード起動後、クラスタウェアリソースの状態を確認します。
$ crsctl stat res -t
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
dbvagent
1 ONLINE ONLINE node1
dbvnet
1 ONLINE ONLINE node1
※表示の都合上、Dbvisit Standby関連のリソースのみ抜粋しております。
こちらでdbvnet・dbvagentがnode1に戻っていることが確認できます。
ログ適用確認の為、ログスイッチを行います。
SQL> select instance_name, status from v gv$instance; INSTANCE_NAME STATUS -------------- ------- ORCL1 OPEN ORCL2 OPEN SQL> alter system switch logfile; システムが変更されました。 SQL> alter system switch logfile; システムが変更されました。 SQL> alter system switch logfile; システムが変更されました。 SQL> exit
Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。

Dbvisit Standbyのデーモンがログ適用を実施するのを待ちます。
Dbvisit Standbyのデーモンがログ適用を実施するのを待ちます。
Dbvisit StandbyのCentral Consoleからログギャップレポートを確認します。
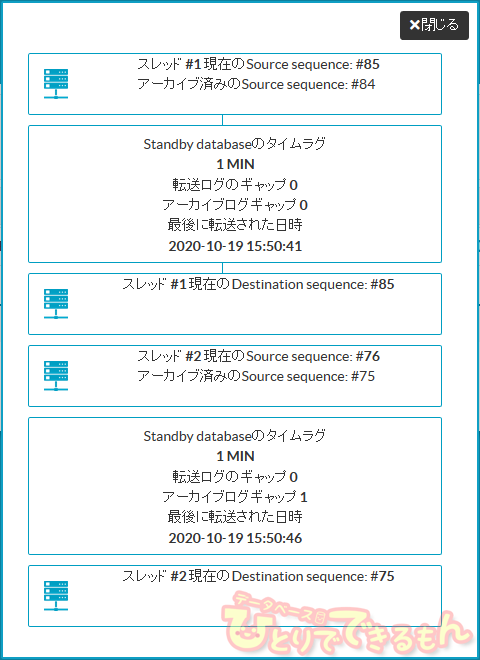
ログギャップがなくなり、ログが適用されたことが確認できます。
こちらで確認ポイントの3つ目である、「ノード障害復旧時、障害発生前の状態に戻ること」が
確認できました!
今回のまとめ
RAC ノード障害時、Dbvisit Standbyが別ノードで起動されること。
切り替え後、ログ適用が自動で行われること。
RAC ノード障害復旧時、障害発生前の状態に戻ること。
上記ポイントが全て実施され、ノード障害発生時でもDbvisit Standbyが正常稼働することが
確認できました!
今回の RAC ノード障害時の動きについてのご紹介は以上となります。
次回は、スタンバイDBの作成(RAC to Single)についてご紹介してみたいと思います。
最後に
Dbvisit Standbyの機能や利用方法・導入・費用については、より詳しい説明をご希望の方は、
どんな些細なことでもお気軽にお問合せ下さい🤵
社内に保守体制もあり、Dbvisit Standbyに精通した専門の技術者がお答えします。
『この環境・構成でも問題なく利用できるか』など是非お気軽にお問い合わせ下さい。
ここまでご覧頂き、ありがとうございました😆
投稿者プロフィール
-
「親しみやすさと技術力」をテーマに、技術情報・サービス・インフラ系資格取得に役立つ情報、社員等の情報をお届けします。
90名強の事業部員で鋭意、執筆中です。
少しでも当社を知って頂けるよう、愛情込めて頑張ります!
※facebook、X(旧twitter)、インスタグラムでは「DBひとりでできるもん」の更新情報を発信しています。
最新の投稿
 Oracle2026年1月7日ORACLE MASTER Silver DBA 2019を取得しました!
Oracle2026年1月7日ORACLE MASTER Silver DBA 2019を取得しました! 26ai2026年1月6日【速報】Oracle AI Database 26ai、オンプレミス対応へ
26ai2026年1月6日【速報】Oracle AI Database 26ai、オンプレミス対応へ お知らせ2026年1月5日新年、明けましておめでとうございます
お知らせ2026年1月5日新年、明けましておめでとうございます 資格取得2025年12月26日Google Cloud Certified Generative AI Leaderを取得しました!
資格取得2025年12月26日Google Cloud Certified Generative AI Leaderを取得しました!