 宮井 聡
宮井 聡
はじめに
みなさん、こんにちは。
AI検証チームの宮井です。
今回はOracle AI Data Platform (AIDP)の2回目の記事ということで、
AIDPのノートブック機能で、Oracleのアラートログのサンプルを使って分析を試してみたいと思います。
サービスが出たばかりの検証ということで最適でない部分もあるかもしれませんが、ご了承ください。
Oracle AI Data Platformの1記事目はこちら!

Oracle AI Data Platformの検証
Oracle AI Data Platformは、Oracleが提供するクラウド(Oracle Cloud Infrastructure)上のデータ分析基盤です。
大規模なデータ処理やAI・機械学習の活用を支援し、データの収集から分析、可視化までを一貫して行えます。
今回の検証では、Oracleのアラートログをオブジェクトストレージから読み込み、Apache Sparkを使って解析・集計し、結果をテーブルに保存して可視化します。
Oracleのアラートログは、データベースの稼働状況やエラー情報を記録した重要なログファイルです。問題発生時の原因調査や運用監視に欠かせません。
今回は、オブジェクトストレージにサンプルのアラートログを格納したものを分析してみます。
テキスト形式で保存されたものを使用しておりますが、日時とメッセージが改行されており、そのまま取り込めないため、加工し、データとして格納します。
まず、ノートブックの作成ですが、ワークスペースから+マークでNotebookの作成をします。
ノートブックでは、以下のようにPythonやSQLを使って記述することができます。
コマンドや構文などは基本的に以下のGithubのページを参考にしております。
GitHub - oracle-samples/oracle-aidp-samples: Oracle AI Data Platform Samples
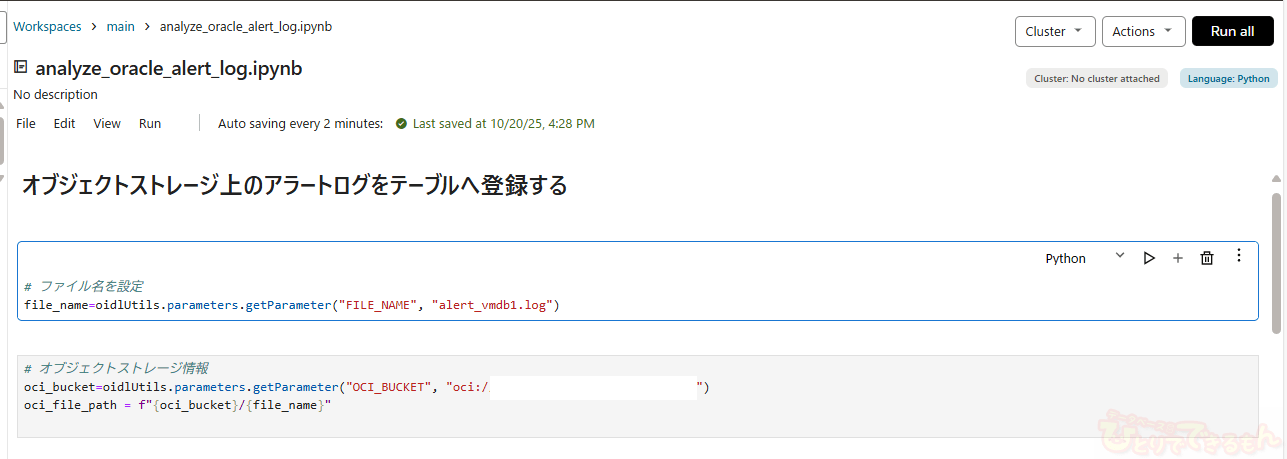
画像だと見づらい部分もあるため、コマンドの形式でご紹介します。
Oracle Cloud Infrastructure(OCI)のオブジェクトストレージに保存されたログファイルを読み込むための変数をセットします。
# ファイル名を設定
file_name=oidlUtils.parameters.getParameter("FILE_NAME", "<アラートログファイル名>")
# オブジェクトストレージ情報
oci_bucket=oidlUtils.parameters.getParameter("OCI_BUCKET", "oci://<バケット名>@<ネームスペース名>")
oci_file_path = f"{oci_bucket}/{file_name}"
次にアラートログの解析部分です。
AIによるコード生成をしており、とりあえず動くところまでしか確認しておりませんが、
やっていることとしては、アラートログの日付とその後に続くメッセージを抽出し、列として格納します。
日付はタイムスタンプ型に変換し、扱いやすくしています。
PySparkでは、DataFrameにデータを格納することで様々な操作に対応することができます。
# アラートログ解析部分
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType
from pyspark.sql.functions import col,to_timestamp
import re
spark = SparkSession.builder.appName("OracleAlertLogParser").getOrCreate()
# ログファイル読み込み
lines_rdd = spark.read.text(oci_file_path).rdd.map(lambda r: r[0])
# 日時の正規表現
timestamp_pattern = re.compile(r"^[A-Z][a-z]{2} [A-Z][a-z]{2} \d{1,2} \d{2}:\d{2}:\d{2} \d{4}$")
# 日時とメッセージの抽出
def group_messages(lines):
entries = []
current_timestamp = None
current_message = []
for line in lines.collect():
if timestamp_pattern.match(line):
if current_timestamp:
entries.append((current_timestamp, "\n".join(current_message)))
current_timestamp = line
current_message = []
else:
current_message.append(line)
if current_timestamp and current_message:
entries.append((current_timestamp, "\n".join(current_message)))
return entries
# DataFrameに変換
grouped_rdd = spark.sparkContext.parallelize(group_messages(lines_rdd))
schema = StructType([
StructField("timestamp", StringType(), True),
StructField("message", StringType(), True)
])
df = spark.createDataFrame(grouped_rdd, schema)
spark.conf.set("spark.sql.session.timeZone", "Asia/Tokyo")
spark.conf.set("spark.sql.legacy.timeParserPolicy", "LEGACY")
df = df.withColumn("timestamp_dt", to_timestamp("timestamp", "EEE MMM dd HH:mm:ss yyyy"))
# 全件表示
df.show(truncate=False)
df.showで得られた結果は以下の通りです。
日時とメッセージが抽出できています。

次に解析結果を保存し、SQLで簡単に参照できるようにテーブルに登録します。
まずスキーマを作成し、DataFrameの必要なカラムだけを抽出して保存します。
冗長的な書き方をしてしまいましたが、selectコマンドでも保存できていることが確認できます。
カタログデータは、カタログ名.スキーマ名.テーブル名という形式で扱うことができます。
# カタログの作成 %sql create schema if not exists ai_catalog.test1
# 置換後のタイムスタンプとメッセージのみ格納
df.select(
col("timestamp_dt").alias("log_time"),
col("message").alias("log_message")
).write.mode("overwrite").saveAsTable("ai_catalog.test1.db_alert")
# テーブルへ登録
df.select(
col("timestamp_dt").alias("log_time"),
col("message").alias("log_message")
).write.insertInto("ai_catalog.test1.db_alert")
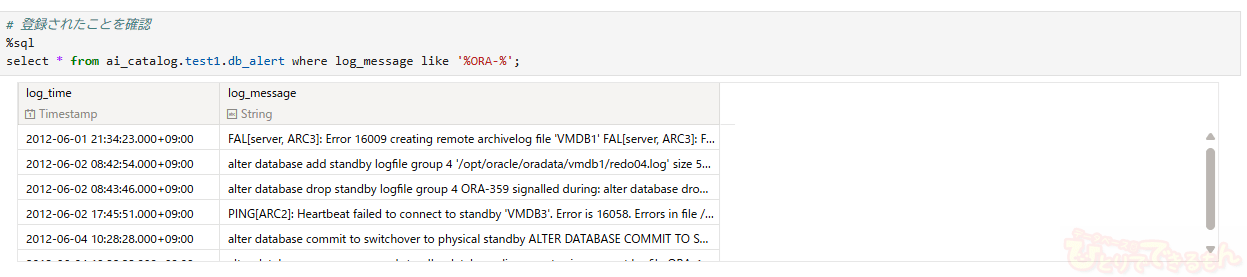
# 登録されたことを確認
%sql
select * from ai_catalog.test1.db_alert where log_message like '%ORA-%';
以下のようにテーブルにデータが格納されました。
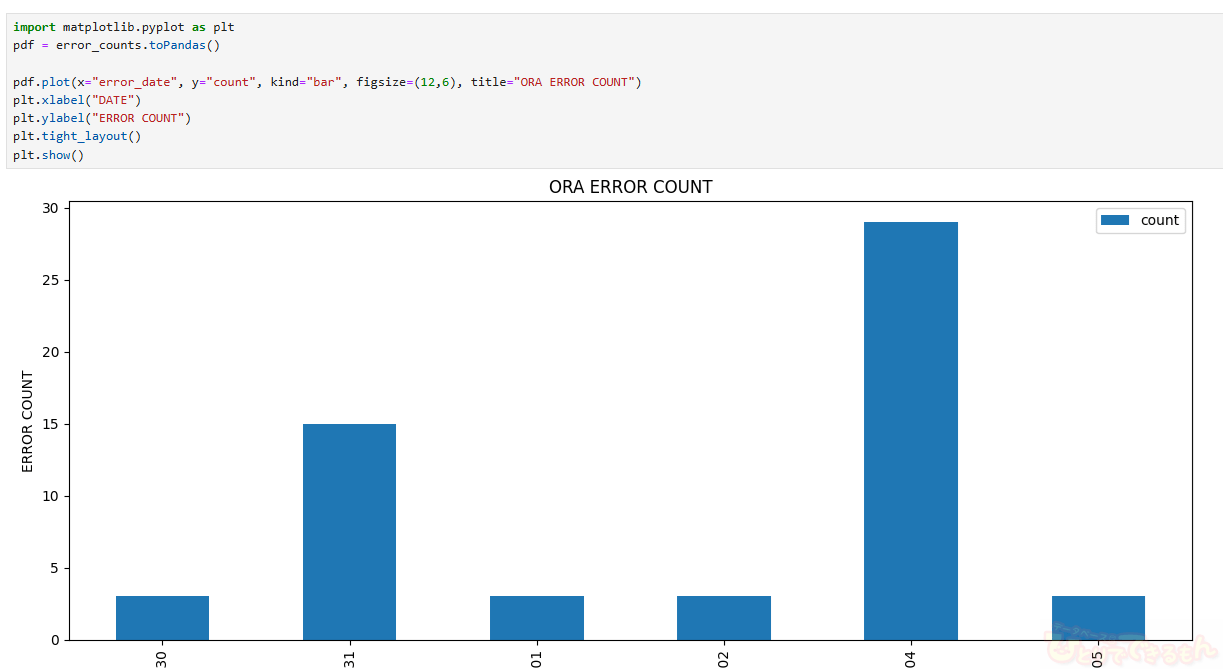
他にもグラフで可視化をしてみます。
Oracleのエラーコード「ORA-」を含むメッセージだけを抽出し、日付ごとにエラー件数を集計します。
グラフ化は、matplotlibを使用します。
from pyspark.sql.functions import col
from pyspark.sql.functions import to_date
error_df = df.filter(col("message").contains("ORA-"))
error_df = error_df.withColumn("error_date", to_date("timestamp_dt"))
error_counts = error_df.groupBy("error_date").count().orderBy("error_date")
error_counts.show(truncate=False)

!pip install matplotlib
import matplotlib.pyplot as plt
pdf = error_counts.toPandas()
pdf.plot(x="error_date", y="count", kind="bar", figsize=(12,6), title="ORA ERROR COUNT")
plt.xlabel("DATE")
plt.ylabel("ERROR COUNT")
plt.tight_layout()
plt.show()
簡単な例ではありますが、グラフ化も出来ています。
今回はここまでですが、他にもエラー別の状況確認や複数の環境をまとめたり、様々な改善ができそうです。
一連の流れをジョブ化すれば、定期的な分析の自動化をすることもできそうですね
まとめ
いかがでしたでしょうか?
今回はアラートログを使用し、コマンド等を紹介しましたが、様々なデータソースの連携などにより、AIDPの活用方法がもっとあるかと思います。
最後になりますが、弊社にはOracleに詳しいエンジニアが多数在籍しております。何かご不明なことやご興味を持たれたことがございましたら、お気軽にお問い合わせください。
投稿者プロフィール
-
Oracle Database、Oracle Cloud、生成AIに関するエンジニア兼プリセールスなどを担当しています。
社内のOCI検証チームのとりまとめやAI検証チームの技術リーダーをしています。
資格はOracle Cloud Infrastructure Architect Professional 2023等を取得しています。
最新の投稿
 Oracle Cloud2025年10月24日Oracle×AI Trials #07: Oracle AI Data Platformを使ってみました~実践編~
Oracle Cloud2025年10月24日Oracle×AI Trials #07: Oracle AI Data Platformを使ってみました~実践編~- Oracle Cloud2025年10月23日Oracle×AI Trials #06: Oracle AI Data Platformを使ってみました~機能紹介編~
 23ai2025年8月28日Oracle×AI Trials #05: 「SELECT AI」機能を試してみました
23ai2025年8月28日Oracle×AI Trials #05: 「SELECT AI」機能を試してみました- 23ai2025年8月15日Oracle×AI Trials #04: Oracle Database 23ai とOllamaを使い、ローカル環境でRAGを試してみました。
