 「DBひとりでできるもん」運営チーム
「DBひとりでできるもん」運営チーム
新連載が始まります!
たろーちゃんに続き、プラチナホルダーの新連載が始まります。
今回のネタは「VLDBとパーティショニング」です。
是非ともお目通しください!

助けて!ボスにドヤされちまう!
キャサリン「どうしたの?チャーリー。浮かない顔をしてるわね。」
チャーリー「聞いてくれよ、キャサリン。今回新しくデザインしたこの履歴テーブルなんだけど、ホラ、レコード作成日付っていうカラムがあるだろ?
これを条件にして四半期ごとに不要レコードを削除するという運用になったんだが、それが1億件以上あるんだよね・・・。
試しに検証してみたら、何時間待ってもDELETEが終わらないんだ!こんなバッチ処理リリースしたらまたボスにドヤされちまう!」
キャサリン「パーティション・テーブルは検討してみた?」
チャーリー「パーティ・・・何だって?そんなもの知らないよ。僕はさっさとこの忌々しいDELETE野郎の尻を叩いてスティーブの店でご機嫌なピザと一杯やりたいだけなんだよ。」
キャサリン「だから、その履歴テーブル、レコード作成日付でパーティション化すれば過去履歴レコードに対してTRUNCATEやDROPも使えるし、あっという間に終わるわよ。他の業務処理のクエリの高速化も期待できるわね。」
チャーリー「・・・もっと詳しく教えてくれ!」
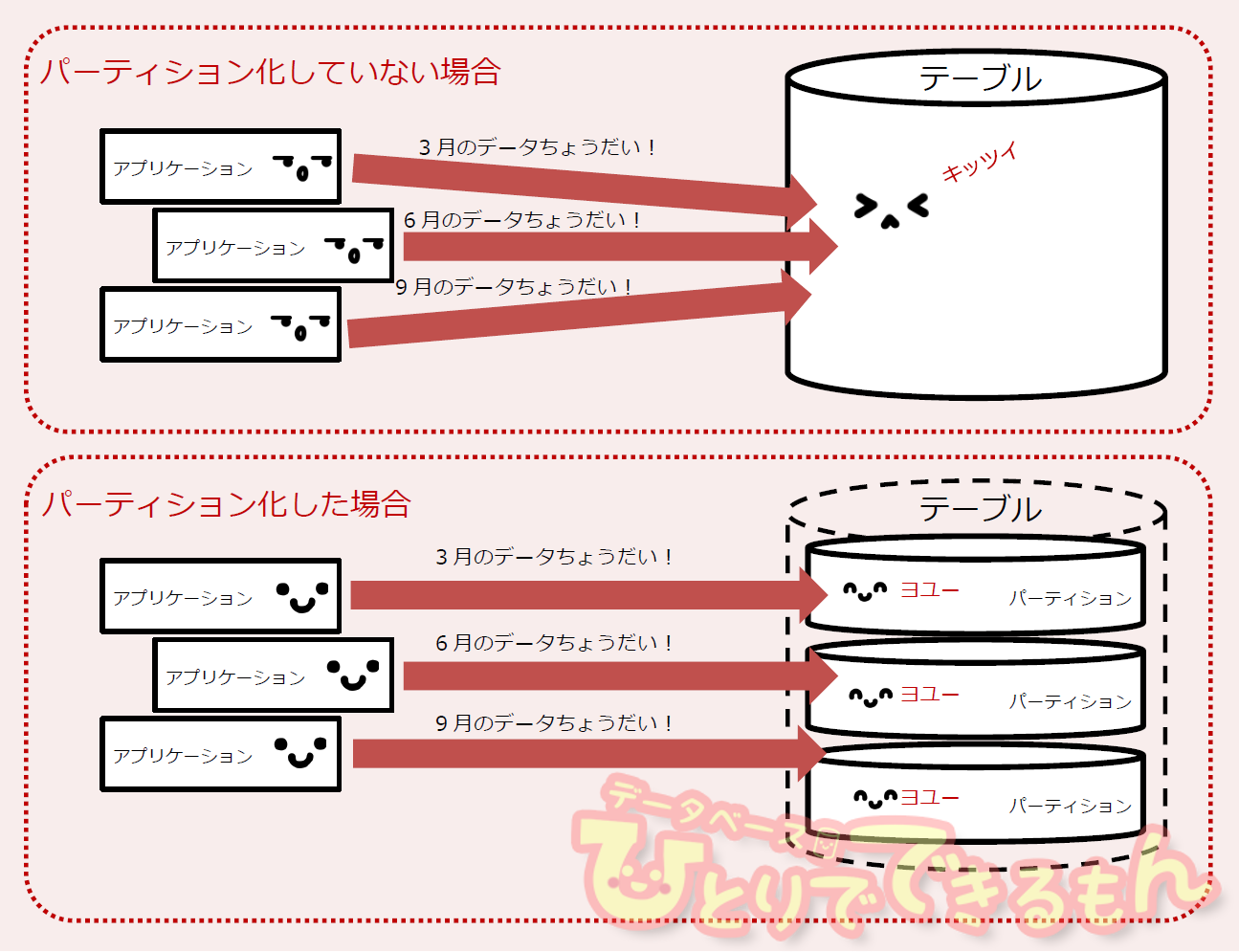
今回紹介する『パーティション化』とは、テーブルの特定のカラムを分割キー(『パーティション化キー』)として、その値の種類によりテーブルを物理的に複数のセグメントに分割することで、クエリやメンテナンス作業のパフォーマンスを向上させる技術です。
利点は様々ありますが、特に大きい以下の2点を挙げておきます。
- SQLによりアクセスする物理領域を一部に限定することで、読み込むブロックを減らし、処理を高速化できる(パーティション・プルーニング)
- パーティションごとに物理セグメントが分割されており、個々のパーティション単位でDROPやTRUNCATEなどの管理作業が行える。
1点目については、アクセスするSQLの条件(WHERE句)にパーティション化キーを指定する必要がある、という条件がありますが、有効な索引がなくFULL SCANとなった場合でも動作するため、SQL要件によっては非常に強力です。
また、1処理でのアクセス範囲を最小限に絞ることができるということは、同様の処理を複数並列に実行しやすく、パラレル処理との相性が抜群ということも言えます。
さらに大事なのは、この機能はアプリケーションから完全に透過的に働くということです。
つまり、実体は分割されていても論理的には1つのテーブルに見えていますので、SQLを書く側は対象のテーブルがパーティション化されていることを意識することなく、同じSQLでも上記条件さえ満たしていればパーティション・プルーニングは有効に作用するということです(もちろん、使う側が知っているに越したことはないのですが)。
2点目については、一つのテーブルだった場合はテーブル全体が対象となってしまうDROPやTRUNCATEをパーティション単位で行うことができ、また他のパーティション作業に影響なく(ロックをかけず)実施できる(並列で実施できる)点が非常に便利となります。
これらの利点はシステムのライフサイクルが進行し、抱えるデータが増大すればするほど威力を発揮します。
なお、パーティショニング機能は、Enterprise Editionの有料オプションですので、Standard Editionなどでは使えません。ご注意ください。
パーティション・テーブルの主な種類
ここではよく使用される主な3種類のパーティションと、その作成方法、選び方をご紹介します。
レンジ・パーティション
キー項目の値の範囲でパーティション分割します。挿入されるレコードの、『このキー項目の値がココまでの値だったらこのパーティション、ココまでならあっちのパーティション』といった具合です。
この、「ココ」をそれぞれのパーティションごとに、キー項目の値が『この値未満であるか』(values less than ~)で指定します。
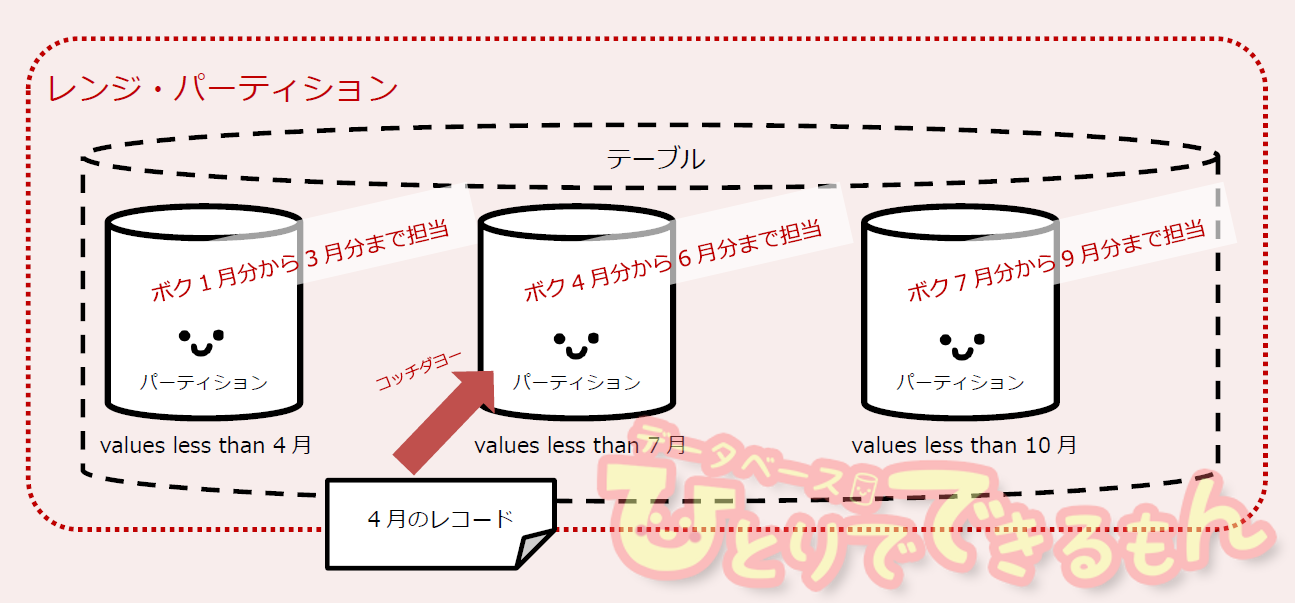
例えば、"4月未満"、"7月未満"、"10月未満"と指定された3つパーティションがあった場合、キー項目が"4月"のレコードは(4月以上)7月未満なので2番目のパーティションに挿入されます。
このレコードの振り分けはもちろん、Oracleが自動でやってくれます。
レンジ・パーティションテーブルを作成するCREATE文のサンプルは以下のようになります。
create table sales ( prod_id number(6), cust_id number, sales_date date, -- これをパーティション化キーとする amount number(10,2), region varchar(30) ) partition by range ( sales_date ) -- "sales_date"をキーとして、"range"パーティション分割する ( partition q1 values less than ( to_date('2019/04/01','yyyy/mm/dd') ) tablespace ts1, partition q2 values less than ( to_date('2019/07/01','yyyy/mm/dd') ) tablespace ts2, partition q3 values less than ( to_date('2019/10/01','yyyy/mm/dd') ) tablespace ts3, partition q4 values less than ( to_date('2020/01/01','yyyy/mm/dd') ) tablespace ts4, partition qmax values less than ( maxvalue ) tablespace ts5 );
赤字の箇所が定型文になります。q1~qmax がパーティション名になります。
ここでは主キーの作成は省略していますが、もちろん主キーを設定することもできます。主キーを含め、パーティション・テーブルに設定する索引については次回以降に説明します。
"maxvalue"は予約語で、直前のパーティション(ここではq4)よりも大きいキー値全てのレコードを担当する"受け皿"として使用することができます。上記例では、2020/1/1以降のレコードは全てここに挿入されます。もし、maxvalueを持つパーティションの作成を省略した場合、2020/1/1のレコードをINSERTしようとするとエラーになります。
また、サンプルから見てもわかる通り、各パーティションごとに配置する表領域を指定することができます。複数パーティションに並列してアクセスする場合、各パーティションを異なる表領域(データファイル)に配置し、物理的にアクセスする領域を分散する施策をとることもあります。
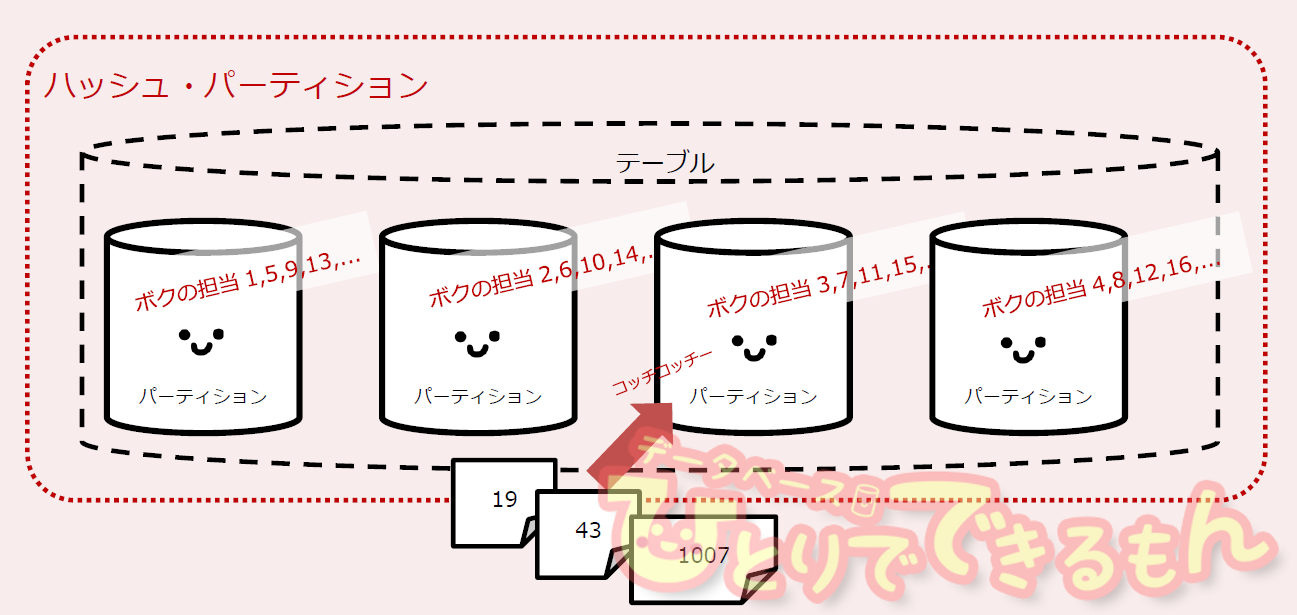
ハッシュ・パーティション
キー項目の値から、決められた数のパーティションに自動的に均等に割り振る分割方式です。レコードが挿入または検索される場合、対象レコードのキー値から、Oracle内部で『ハッシュ化関数』と呼ばれるロジックを通して機械的に対象のパーティションが判別されます。
これにより、無限に近い、あるいは数があらかじめ不明な種類をもつキー値のレコードを一定数のパーティションにほぼ均一に均(なら)すことができるのがハッシュ・パーティションの特長です。
『ハッシュ』ってそもそも何?
一般的に、『ハッシュ化』の一番単純なロジックの代表は、『キー値を分割数で割った余り』で算出することです。
例えば任意の数字を4つのグループ(=パーティション数)に振り分けたい場合、その数(=キー値)を4で割った余りをグループ番号(パーティション番号)とします。1を4で割った余りは1に、5を4で割った余りも1になります。
キー値が1 ⇒ ハッシュ値は1、キー値が2 ⇒ ハッシュ値は2
キー値が3 ⇒ ハッシュ値は3、キー値が4 ⇒ ハッシュ値は4
キー値が5 ⇒ ハッシュ値は1、キー値が6 ⇒ ハッシュ値は2
キー値が7 ⇒ ハッシュ値は3、キー値が8 ⇒ ハッシュ値は4 …
といったように、キー値がまんべんなく存在する場合、その範囲がどんなに広くても、ある決められた数のグループにまんべんなく振り分けられます。
ただし、Oracleのハッシュ・パーティション化で使用されているロジックはもう少し複雑(キー値には文字列も使えます)ですので上記そのままではありません(ロジックは公開されていません)。
ハッシュ・パーティションテーブルを作成するCREATE文のサンプルは以下のようになります。
create table sales ( prod_id number(6), cust_id number, -- これをパーティション化キーとする sales_date date, amount number(10,2), region varchar(30) ) partition by hash ( cust_id ) -- "cust_id"をキーとして、"hash"パーティション分割する ( partition p1 tablespace ts1, partition p2 tablespace ts2, partition p3 tablespace ts3, partition p4 tablespace ts4 );
レンジ・パーティションよりも構文がすっきりしていることから、ハッシュの場合は基本的に分割数以外には(振り分けロジックなどを)ユーザーは指定できない(する必要がない)ことがわかります。
また、さらにパーティション名や配置表領域の指定を簡略化(Oracleまかせに)した構文として、以下のようにも記述することができます。
create table sales ( cust_id number, -- これをパーティション化キーとする sales_date date, amount number(10,2) region varchar(30) ) partition by hash ( cust_id ) partitions 4 -- "cust_id"をキーとして、4つに"hash"パーティション分割する store in ( ts1, ts2, ts3 );
この場合、store in ()内に記述する表領域は分割数と同じ数だけ用意する必要はありません。()内の表領域に自動的に分散して配置されます。
このように、ハッシュ・パーティションは、SQLのアクセスを分散しパーティション・プルーニングなどにより性能を向上したいが、キー値の種類は不特定なため割り振りルールはOracleに任せたい、といった場合に最適です。
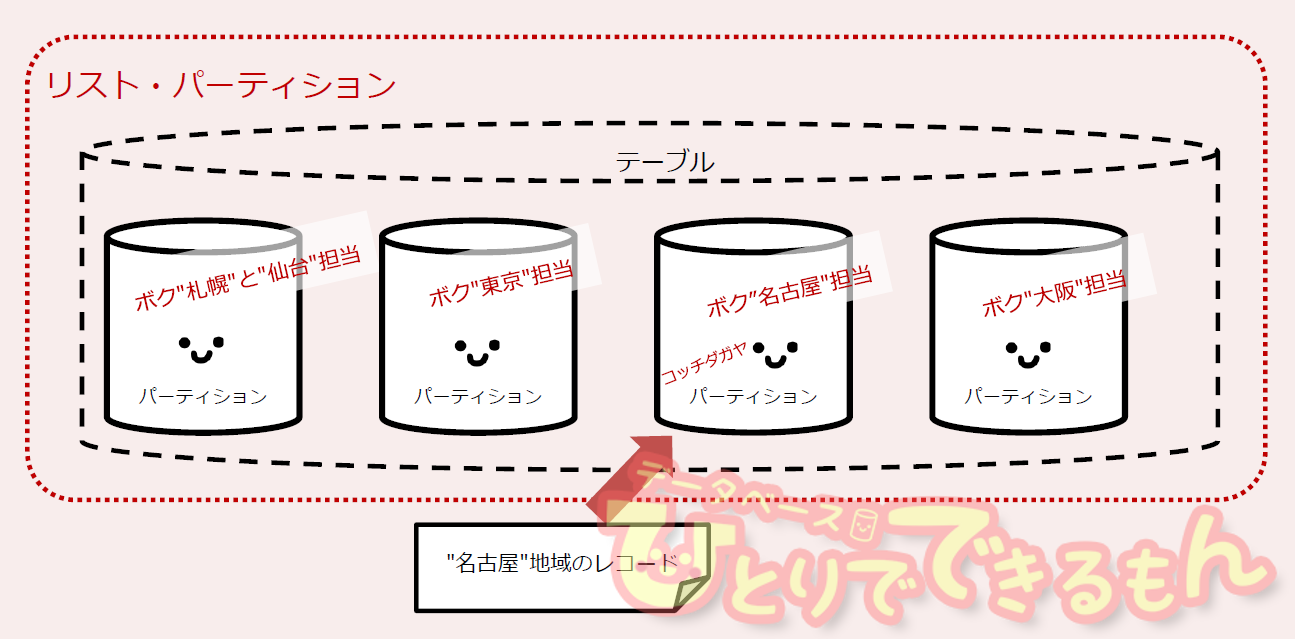
リスト・パーティション
キー項目の値が、事前に決まっている複数の値のどれに該当するか、で分割する方式です。
レンジ・パーティションが連続したキー値で判断するのに対し、リスト・パーティションは完全に固定された、取りうる値をキー値として全てリストアップします。
リスト・パーティションテーブルを作成するCREATE文のサンプルは以下のようになります。
create table sales ( prod_id number(6), cust_id number, sales_date date, amount number(10,2), region varchar(30) -- これをパーティション化キーとする ) partition by list ( region ) -- "region"をキーとして、"list"パーティション分割する ( partition r1 values ( 'Sapporo', 'Sendai' ) tablespace ts1, partition r2 values ( 'Tokyo' ) tablespace ts2, partition r3 values ( 'Nagoya' ) tablespace ts3, partition r4 values ( 'Osaka' ) tablespace ts4, partition r5 values ( 'Fukuoka' ) tablespace ts5, partition r6 values ( default ) tablespace ts6 );
サンプルのように、指定するキー値は一つのパーティションに対して複数指定することができます。上記例ではパーティションr1へは、キー値が'Sapporo'または'Sendai'のどちらがきても挿入されます。
"default"は予約語で、リストされたどのキー値にも当てはまらないレコードを担当する"受け皿"として使用することができます。もし、defaultを持つパーティションの作成を省略した場合、リストにないキー値のレコードをINSERTしようとするとエラーになります。
まとめ
今回はパーティションの基本的な形3つを紹介しました。
それぞれの特長をまとめますと以下のようになります。
| 種類 | 特長 |
| レンジ |
|
| ハッシュ |
|
| リスト |
|
テーブルを分割する目的を明確に把握し、是非最適な分割方式を選択するようにしましょう。
さて、次回ではさらに特殊な形式のパーティションについて触れていきたいと思います。
キャサリン「どう?パーティションの概要、大体わかった?」
チャーリー「よくわかったよ、キャサリン。
よし、僕自身がボスにバラバラにパーティション化される前にさっそく例の履歴テーブルを作成日付でレンジ・パーティション化する方向で再デザインしてみようと思うよ。じゃ。」
キャサリン「あら?どこへ行くの、チャーリー?」
チャーリー「テーブルの分割の前にまずは腹ごしらえにスティーブの店でゴキゲンなピザを僕のお腹へパーティション化してくるよ!」
キャサリン「ちょっとー!パーティションにはまだまだ注意しなきゃいけないことがあるんだからー!全5回の連載の最後までちゃんと見なさいよー!!」
投稿者プロフィール
-
「親しみやすさと技術力」をテーマに、技術情報・サービス・インフラ系資格取得に役立つ情報、社員等の情報をお届けします。
90名強の事業部員で鋭意、執筆中です。
少しでも当社を知って頂けるよう、愛情込めて頑張ります!
※facebook、X(旧twitter)、インスタグラムでは「DBひとりでできるもん」の更新情報を発信しています。
最新の投稿
 資格取得2026年1月9日OCI関連資格3冠に加えOracle Data Platform 2025 Certified Foundations Associate、Oracle AI Vector Search Professionalを取得しました!
資格取得2026年1月9日OCI関連資格3冠に加えOracle Data Platform 2025 Certified Foundations Associate、Oracle AI Vector Search Professionalを取得しました! Infrastructure(IaaS)2026年1月8日【OCI】お知らせサブスクリプションを作ってみました!
Infrastructure(IaaS)2026年1月8日【OCI】お知らせサブスクリプションを作ってみました! Oracle2026年1月7日ORACLE MASTER Silver DBA 2019を取得しました!
Oracle2026年1月7日ORACLE MASTER Silver DBA 2019を取得しました! 26ai2026年1月6日【速報】Oracle AI Database 26ai、オンプレミス対応へ
26ai2026年1月6日【速報】Oracle AI Database 26ai、オンプレミス対応へ

