前回のおさらい
前回は血液検査の結果、log file sync が多発していることが発覚し、さらに該当時間帯のアラートログやトレースファイルを調査すると「Warning: log write broadcast wait time」が多発?!
たろーちゃんがこの謎のメッセージに挑みます。
log file sync の悪夢再び!の完結編、はじまりはじまり~。
メッセージの意味
Aさん「たろーちゃん、あのトレースファイルに出力されていたメッセージは、どういう意味なんだ?」
<再掲>
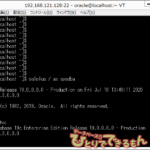
Trace file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_lms0_8860_8865.trc Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.2.0.0.0 Build label: RDBMS_19.2.0.0.0_LINUX.X64_190204 ORACLE_HOME: /u01/app/oracle/product/19.0.0/dbhome_1 System name: Linux Node name: node1 Release: 4.1.12-124.24.3.el7uek.x86_64 Version: #2 SMP Mon Jan 14 15:04:40 PST 2019 Machine: x86_64 Storage: Exadata Instance name: orcl1 Redo thread mounted by this instance: 0 Oracle process number: 26 Unix process pid: 8860, thread id: 8865, image: node1 (LMS0) *** 2019-11-01 10:33:36.241 (CDB$ROOT(1)) *** SESSION ID:(332.19470) 2019-11-01 10:33:36.241 *** CLIENT ID:() 2019-11-01 10:33:36.241 *** SERVICE NAME:() 2019-11-01 10:33:36.241 *** MODULE NAME:() 2019-11-01 10:33:36.241 *** ACTION NAME:() 2019-11-01 10:33:36.241 *** CLIENT DRIVER:() 2019-11-01 10:33:36.241 *** CONTAINER ID:(1) 2019-11-01 10:33:36.241 * KJM HIST - Cheap us TRUE Cheap sec TRUE *** 2019-11-01 14:41:54.158 (CDB$ROOT(1)) Warning: log write broadcast wait time 511ms (SCN 0x2cfea0f0) *** 2019-11-01 14:41:48.261 (CDB$ROOT(1)) Warning: log write broadcast wait time 2427ms (SCN 0x2cfeeecc) *** 2019-11-01 14:42:39.574 (CDB$ROOT(1)) Warning: log write broadcast wait time 2178ms (SCN 0x2cffeda4) *** 2019-11-01 14:43:36.961 (CDB$ROOT(1)) Warning: log write broadcast wait time 2046ms (SCN 0x2d00e74c) *** 2019-11-01 14:44:07.240 (CDB$ROOT(1)) Warning: log write broadcast wait time 2611ms (SCN 0x2d01b144) *** 2019-11-01 14:44:07.247 (CDB$ROOT(1)) Warning: log write broadcast wait time 2596ms (SCN 0x2d01b1a2) *** 2019-11-01 14:44:25.357 (CDB$ROOT(1)) Warning: log write broadcast wait time 1125ms (SCN 0x2d021b10) *** 2019-11-01 14:45:07.484 (CDB$ROOT(1)) Warning: log write broadcast wait time 674ms (SCN 0x2d033304) *** 2019-11-01 14:45:08.142 (CDB$ROOT(1)) Warning: log write broadcast wait time 826ms (SCN 0x2d0544c2) *** 2019-11-01 14:45:32.300 (CDB$ROOT(1)) Warning: log write broadcast wait time 2371ms (SCN 0x2d05b002) *** 2019-11-01 14:46:05.400 (CDB$ROOT(1)) Warning: log write broadcast wait time 1317ms (SCN 0x2d05ff64) *** 2019-11-01 14:46:32.709 (CDB$ROOT(1)) Warning: log write broadcast wait time 759ms (SCN 0x2d070890) ::: ::: ::: (略)
Aさん「トレースファイルのファイル名から察するに、LMS というバックグラウンドプロセスのようだけど・・・。」
たろー「その通り。これは LMS バックグラウンドプロセスが出力しているメッセージだ。」
Aさん「それに、なんだこのファイル名は?『orcl1_lms0_8860_8865.trc』って、やけに数字が多いな。他のバックグラウンドプロセスのトレースファイルはプロセスIDだけなのに。」
たろー「LMS バックグラウンドプロセスは 18c からマルチスレッド化されたんだよ。ファイル名の後ろに付いている数字は、<プロセスID>_<スレッドID>なんだ。」
Aさん「へぇー。バージョンアップの度に色々変わってるんだなぁ。
・・・で、LMS バックグラウンドプロセスって何者なんだ?」
たろー「LMS バックグラウンドプロセス は RAC インスタンス間でのメッセージの流れを制御する役割を担ってるんだよ。」
※LMS バックグラウンドプロセスに関しては、以前の記事『RACのリコンフィグ』の回をご参照下さい。
Aさん「メッセージの流れ?」
たろー「そうだ。 RAC の場合、COMMIT が実行されると、SCN の同期を取るために、全インスタンスにブロードキャストメッセージを送信するんだ。」
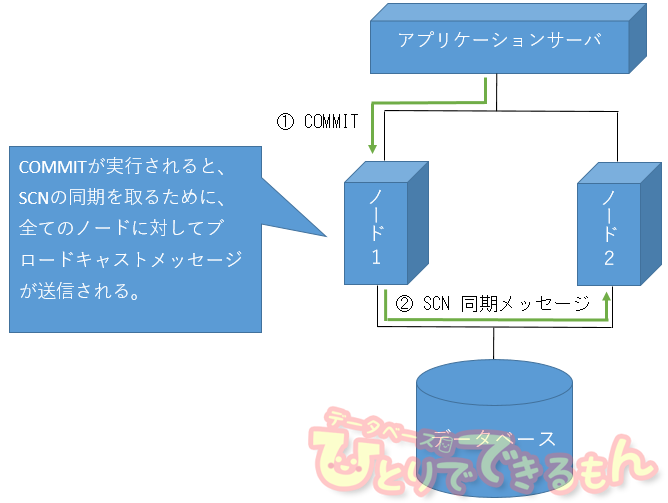
たろー「そして、そのメッセージを受け取ったノードは、ACK(応答メッセージ)を返す。」

たろー「ACK(応答メッセージ)を受け取ったノードは、そこで初めて REDO ログファイルに書き込みを行う仕組みなんだ。」
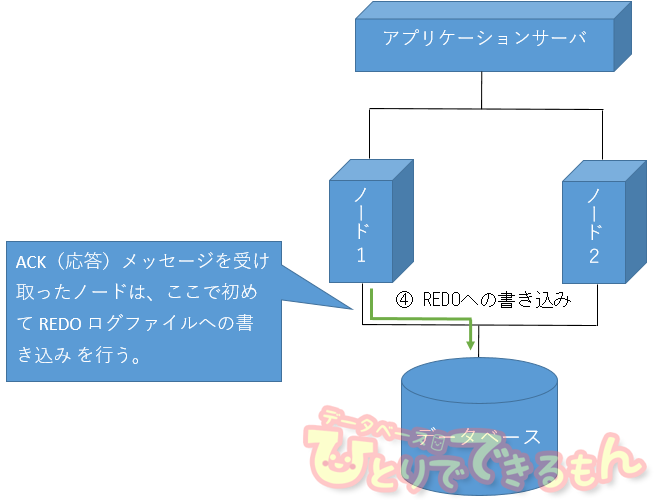
Aさん「なるほどなぁ。そういう仕組みなのか。」
たろー「トレースファイルに出力されていた Warning メッセージ、『log write broadcast wait time』は、ブロードキャストしたメッセージに対する ACK(応答)が 長時間返ってこなかった場合に出力されるメッセージだ。これは My Oracle Support のドキュメントID 1590052.1に記載されている情報だ。」
Aさん「なんだって?!」
たろー「メッセージが出力される閾値は、500ミリ秒だ。500ミリ秒以上経過した場合にあのメッセージが出力されるんだよ。」
Aさん「ほう。」

たろー「と、いうことは、だ。」
たろーちゃんは、もう一度 AWR レポートを開きました。

たろー「やっぱり、インスタンスの統計情報『redo write broadcast ack time』の値が異常に高いな。これは ACK(応答)メッセージを受け取るまでの時間を現しているんだ。何らかの問題で、ACK(応答)メッセージを受け取るまでに時間が掛かっているのだろう。」
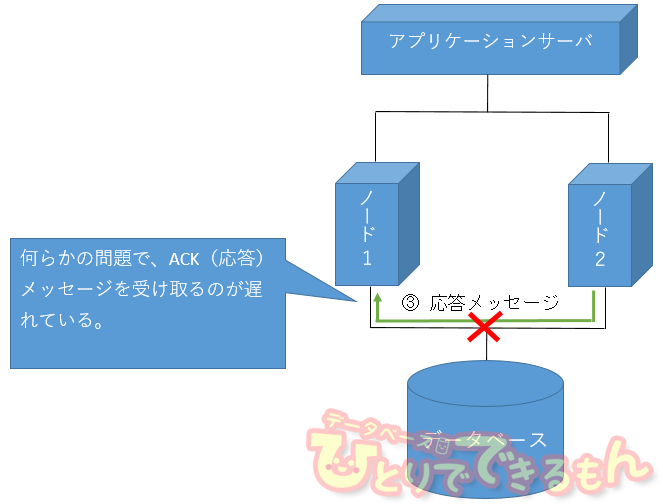
たろー「ACK(応答)メッセージを受け取れないと、COMMIT を行うことが出来ないから、それが結果として log file sync 待機イベントとして現れているんだよ。」
Aさん「ということは、ネットワーク回線の問題だな!」
待て、あわてるな、これは罠だ!

たろー「いや、そう決めつけるのはまだ早い。サーバ側の負荷も関係するしな。サーバ管理者とネットワーク管理者に調査を依頼して、その時間帯に回線が輻輳状態だったり、サーバが高負荷状態だったりしないか、調べてもらおう。」
たろーちゃんとAさんは、それぞれサーバ管理者とネットワーク管理者に調査を依頼しました。
調査結果は?
Aさん「調べてもらったよ、たろーちゃん。」
たろー「どうだった?」
Aさん「なんら問題なしだった。ネットワークも輻輳してなかったし、サーバもアクセスを寄せているノード1の負荷がちょっと高いだけで、CPU にもメモリにも余裕があった。ノード2においてはスカスカの状態だったよ。」
たろー「ふーむ、一体何が ACK (応答)メッセージを妨げているんだ?」
首を傾げるたろーちゃん。

原因の切り分け
たろー「Aさん。原因の切り分けのために、試しにインスタンス2を shutdown して処理を流してみないか?」
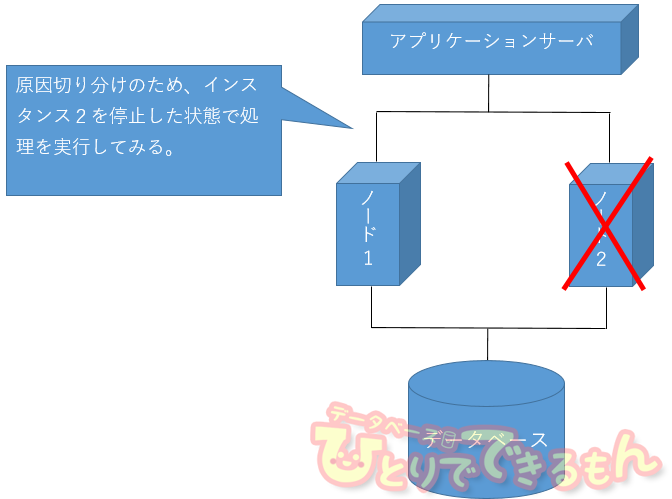
Aさん「ああ、構わないよ。やってみよう。」
たろーちゃんはインスタンス2を shutdown し、Aさんは処理を実行しました。
Aさん「おお、早い!もう処理が終わったぞ。」
たろー「やはり ACK(応答)メッセージの問題だな。 AWR レポートを見てみたけど、インスタンスの統計情報『redo write broadcast ack time』は発生していなかった。」
Aさん「通信する相手がいないから、LMS バックグラウンドプロセスが SCN の同期を取る必要がないからだな?」
たろー「そういうことだ。」
Aさん「ふーむ・・・。」
たろー「・・・。」
Aさん「・・・。」
たろー「・・・・・・。」
Aさん「・・・・・・。」
たろー「・・・・・・・・・。」
Aさん「・・・・・・・・・。」
・・・よ、よーし、問題解決だ!
これからは、インスタンス2はずっと停止したままで運用しよう!

冗談、顔だけにしろよ!

Aさん「何のための RAC 構成だよ?!」
たろー「う、嘘だって。そんなに怒るなよ。」
Aさん「まったく・・・!」
たろー「そうだなぁ・・・。更なる原因の切り分けのために、
今度は処理を片系に寄せるんじゃなくて、一般的な RAC 構成で行うような方式・・・、つまり両系に処理を均等に振るようにしてみてくれないか?」
Aさん「ああ、それなら簡単だ。データベースへの接続情報を変更するだけだからな。」
たろーちゃんはインスタンス2を startup し、Aさんはアプリケーションサーバのデータベース接続情報を変更して処理を実行しました。
すると・・・。
Aさん「お、まあまあ早いな。
さっきの1インスタンスだけの時ほどじゃないが、片系に寄せるよりは全然早い。」
たろー「なるほどな・・・。LMS バックグラウンドプロセスのトレースファイルにも Warning メッセージは出力されていない。 AWR レポートも見てみたけど、インスタンスの統計情報『redo write broadcast ack time』がかなり小さくなっていた。その代わり、Aさんが心配していたように、gc 系の待機イベントが多発してボトルネックになっている。」
Aさん「一体、どういうことなんだ?」
たろー「処理を両系に振ることで、SCN 同期メッセージを相互に送るようになったんだ。そうすると、お互いに嫌でも ACK(応答)メッセージを返さざるを得なくなる。片系に処理を寄せたケースでは、おそらく何らかの問題で、ACK(応答)メッセージをインスタンス2が返せていないのだろう。」
Aさん「??そんなことがあるのか?」
たろー「うーむ・・・。Aさん、処理を片系に寄せるように戻してくれるか?
ちょっと試したいことがあるんだ。」
Aさん「ああ、わかった。」

Aさんはアプリケーションサーバのデータベース接続情報を元に戻しました。
Aさん「処理を実行していいか?」
たろー「もうちょっと待ってくれ。今、インスタンス2に『あるもの』を仕掛けているから・・・。」
Aさん「『あるもの』?」
たろー「出来た!Aさん、今の状態で処理を流してみてくれ。」
Aさん「ああ、分かった。」
Aさんはアプリケーションサーバで処理を実行しました。
すると・・・。
Aさん「うお!すごく早くなったぞ!」
たろー「・・・やっぱりか・・・。」
Aさん「たろーちゃん、インスタンス2に何をしたんだ?!」
たろー「いや、大したことをした訳じゃない・・・。
俺だって未だに信じられないんだ・・・。まさかそんなことがあるのだろうか??」

たろーちゃんは何をしたのか?
たろーちゃんはインスタンス2上で、ダミートランザクションをループする処理を PL/SQL で実装しただけでした。
なぜそれでパフォーマンスが改善されたのでしょうか?
たろー「俺はインスタンス2で、この無名 PL/SQL ブロックを実行しただけなんだ・・・。」
begin
loop
update TEST_TBL set FLG = 'X' where ID = 1;
commit;
dbms_lock.sleep(0.01);
end loop;
end;
/
は?
たろー「ダミーの TEST_TBL というテーブルを作って、それに対して 10 ミリ秒毎に UPDATE&COMMIT する。ただそれだけの処理だ。」
Aさん「なぜそれで、インスタンス1で実行している処理が早くなるんだ???」
たろー「こんな感じで、10ミリ秒毎に強制的にACK(応答)メッセージを発生させてるんだよ。」
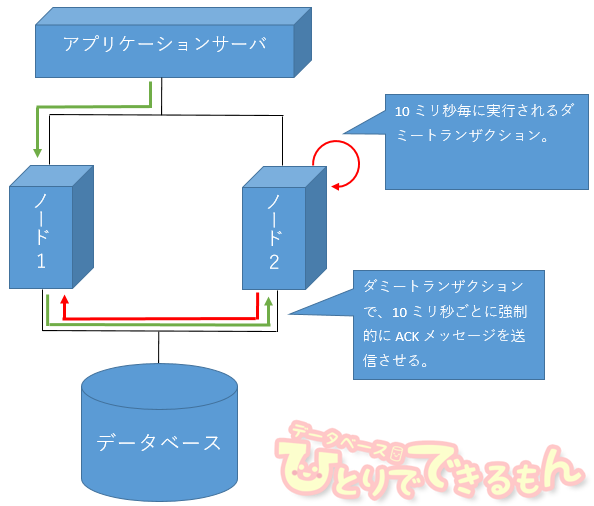
Aさん「何?! RAC ってそういうものなのか??」
たろー「いや、そんな筈はない。こんな泥臭いことをしないとパフォーマンスが出ないなんて、おかしいんだ。」
Aさん「どういうことだ?」
たろー「すまん、正直これ以上は分からない・・・。
Aさん。とりあえず、処理を実行する時はこんな感じで、インスタンス2に対してダミートランザクションを発生させるようにしてくれないか?他にいい方法が見つからないんだ・・・。」
Aさん「うむ、分かった。それくらいのことなら朝飯前だ。それをワークアラウンドにさせてもらうよ。」
Aさんはたろーちゃんの提案どおりにダミートランザクションを実装し、システムのパフォーマンスは改善されました。
今まで数々の問題を解決してきたたろーちゃんでしたが、今回はワークアラウンドを見つけ出すだけで精一杯。根本的な問題を解決することが出来ませんでした・・・。
今回の「心臓外科医の術式」いかがだったでしょうか?
まるで奥歯のあいだに物が挟まったような、なんともスッキリしない結末でしたね。
しかし残念ながら、原因不明な症状が出ることは、実際にあります。
そんな時は、なんとかワークアラウンドを見つけ出すしかありません。そのためには、やはり Oracle Database(特に RAC )がどのようなメカニズムで動作しているかを理解しておく必要があります。メカニズムを理解していれば、ワークアラウンドを見つけやすくなるためです。
それでは次回も頑張りますので、応援よろしくお願い致します。
クックックッ。
今回は私の勝ちだね。
くそー!!
悔しいー!!

投稿者プロフィール