 「DBひとりでできるもん」運営チーム + 責任者_山本
「DBひとりでできるもん」運営チーム + 責任者_山本
前回のおさらい
前回は データベースリンク を使うアプリケーションが、開発環境よりリソース豊富な本番環境のほうが、実行時間が極端に長くなるという不可解な謎が起こっていました。
たろーちゃんはこの謎をどのように解決に導いていくのでしょうか
「強敵!log file sync」完結編です。
調査続行
Aさん「どうするんだ、たろーちゃん?」
たろー「うーむ・・・。念のため確認だけど、」
① データベースリンク 先のテーブルから処理対象となるレコードを読み込む
② ①の情報に従って データベースリンク 元のテーブルを INSERT or UPDATE
③ ①の情報を処理済みとして UPDATE
④ COMMIT を実施
たろー「①の処理は、SELECT ~ FOR UPDATE を使っているか?」
Aさん「いや、SELECT ~ FOR UPDATE は使っていない。単純な SELECT だよ。」
たろー「となると、saki データベース側は③からトランザクションが始まっていることになるのか・・・。」
頭をひねるたろーちゃん。
たろー「・・・・・・・・。とりあえず、基本に戻ろう。log file sync については My Oracle Support のドキュメントID 1911629.1 に対処方法が書かれている。 AWR の情報を元に、調査を進めよう。」
◆本番環境
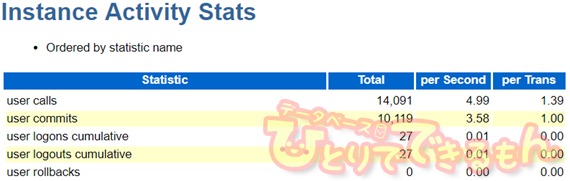
たろー「ドキュメントID 1911629.1 によると、
『"user calls/(user commits + user rollbacks)" として計算される commit/rollback あたりの平均 user calls が 30 未満の場合は、commit が非常に頻繁に行われています。』
と書かれている。」
Aさん「えーっと、その式に値をあてはめると・・・。」
14,091 / (10,119 + 0 ) ≒ 1.3925
Aさん「となる。全然30未満だな。」
たろー「教科書どおりだと、『 commit 回数が多い』ってことになるんだが・・・Aさん。
このアプリケーションの COMMIT 回数を減らすなんてこと出来るか?」
Aさん「それって、トランザクションの数を減らすってことだよな?」
たろー「そうだ。」
Aさん「それは無理だ。アプリケーションの仕様で、今の COMMIT の粒度は守らないといけない。」
たろー「だよなぁ・・・。 COMMIT の回数を減らせれば、そんな苦労しないよな。」
Aさん「うん。」
たろー「そもそも開発環境を見てみると、」
◆開発環境
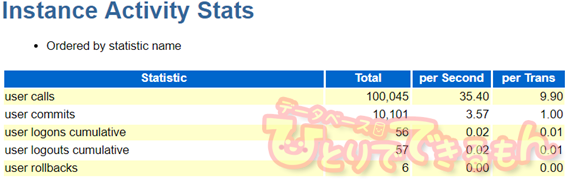
100,045 / (10,101 + 6 ) ≒ 9.898
たろー「これも全然30未満だ。本番環境で発生している遅延は、 COMMIT 粒度が原因とは思えない。」
Aさん「ドキュメントID 1911629.1 を一通り読んでみたけど、これ以上、有益な情報はなさそうだな。」
たろー「うん。 IO が ボトルネック じゃないし、REDO ログファイルのサイズも問題ない。」

たろー「更新が多ければ、LGWR が待たされる log file parallel write に時間が掛かる筈だけど、5秒しかかかってない。またログスイッチ時に アーカイブログ ファイルを ARCH が作成するために、log file sequential read っていう待機イベントも上昇する筈なんだ。それが正しい IO 負荷の掛かり方だ。」
Aさん「ふむ。」
たろー「それらが無いってことは、 IO の問題じゃないってことだ。どうしてこれで、本番環境は遅くて、開発環境は早いなんて事象が起こるんだ??」
たろー「(髪の毛をクシャクシャかきながら、)あー、もう、わっかんねー!!・・・。」

深夜のオフィスに重苦しい空気が漂います。。。
たろー「・・・だめだ、Aさん。気分を変えよう。フロアの明かりを消すぞ。」
Aさん「は??」
たろー「俺、部屋を真っ暗にして考えたら集中力が増すんだ。本気でパフォーマンスチューニングする時はいつもそうしてる。」
Aさん「??」
たろー「まぁ、俺はそれを『ブラインド・アタック』って呼んでるけどな。」

Aさん(うわぁ・・・。中二病だ・・・。)

たろー「あばれ〇っちゃくだって、考え事をする時に逆立ちするだろ?あれと同じだよ。」

Aさん「〇ばれはっちゃくなんて、今どき誰も知らないだろう・・・。
歳がバレるぞ、たろーちゃん。」
たろーちゃんはフロアのライトを消し、パソコンに向かいます。
たろー「・・・うーむ。SQL の実行計画が悪いとか、 IO が ボトルネック とかの問題なら対処のしようもあるんだけど、ただ単に COMMIT が遅いとなると、単純に LGWR が処理をサボってるとしか思えないな。」
Aさん「ほう、LGWR か・・・。」
Aさん(カタカタカタ)
Aさん「・・・あれ?」
たろー「どうした?」
Aさん「いや、LGWR ってこれだよな?」
$ ps -ef | grep lg | grep moto
oracle 74160 1 0 May02 ? 00:05:10 ora_lgwr_moto
oracle 74187 1 0 May02 ? 00:11:01 ora_lg00_moto
oracle 74230 1 0 May02 ? 00:00:14 ora_lg01_moto
oracle 74239 1 0 May02 ? 00:00:14 ora_lg02_moto
oracle 74275 1 0 May02 ? 00:00:14 ora_lg03_moto
oracle 74307 1 0 May02 ? 00:00:50 ora_lg04_moto
oracle 74313 1 0 May02 ? 00:00:14 ora_lg05_moto
oracle 74320 1 0 May02 ? 00:00:14 ora_lg06_moto
oracle 74338 1 0 May02 ? 00:00:14 ora_lg07_moto
たろー「ああ、そうだよ。」
Aさん「数字が付いてる lg00~lg07 ってなんだ?こんなバックグラウンドプロセスあったっけ?」
たろー「それは Scalable Log Writer といって、12c からの新機能だ。」
Aさん「12c からの新機能?」
たろー「従来は LGWR が全ての処理を担ってたんだけど、12c からは REDO ログの書き込みは、その数字が付いた Worker Process に任せるようになったんだよ。それで REDO ログの書き込みパフォーマンスが向上しているんだ。」
Aさん「だから今まで見たことがなかったのか。」
たろー「・・・!!待てよ!」
Aさん「どうした?」
たろーちゃんは、開発環境にログインしました。
たろー(カタカタカタ)
$ ps -ef | grep lg | grep moto
oracle 64160 1 0 May02 ? 00:06:10 ora_lgwr_moto
oracle 75187 1 0 May02 ? 00:16:01 ora_lg00_moto
oracle 74260 1 0 May02 ? 00:01:14 ora_lg01_moto
Aさん「Worker Process の数が本番環境より少ないな。」
たろー「Aさん、本番環境はリソースが潤沢で、開発環境は本番環境より劣るって言ったよな?」
Aさん「ああ。」
たろー「CPU の数はどうなんだ?」
Aさん「CPU の数は、本番環境が14で、開発環境は2だ。」
たろー「もしかしたら・・・。Aさん、本番環境で試してみたいことがあるんだ。本番環境のインスタンスを今、再起動してもいいかな?」
Aさん「インスタンスを?まぁ今の時間帯なら何の処理も走ってないから、構わないよ。」
たろー「よし。」
たろー(カタカタカタ)
たろーちゃんは、とある設定を変更し、本番環境のデータベースインスタンスを再起動しました。
たろー「Aさん。この状態でダミー処理を流してみてくれ。」
Aさん「またか? 1時間コースになるぞ?」
たろー「いいから、流してみてくれ。」
Aさん「分かった。」
たろーちゃんの言う通り、Aさんはダミー処理を実行することにしました。
すると・・・。
Aさん「あれ?!もう処理が終わった!」
たろー「・・・やはりか。」
Aさん「開発環境と同じ早さになったぞ。たろーちゃん、一体何をしたんだ??」
たろー「・・・。謎は、全て解けた!」
原因究明
たろーちゃんが変更したのは、_use_single_log_writer という隠しパラメータでした。
このパラメータは LGWR の動作を制御するもので、
- TRUE 常に LGWR が REDO ログファイルへの書き込みを担う。従来の動作。
- FALSE 常に一旦 LGWR が要求を受けて、LGnn が REDO ログファイルへ書き込む。
- ADAPTIVE 両者を動的に切り替える。12c 以降のデフォルト値。
となっています。たろーちゃんはこのパラメータを TRUE に変更し、LGWR の動作を従来型にしたのです。
Aさん「でも、たろーちゃん。Scalable Log Writer だとどうして遅いんだ?」
たろー「おそらく、プロセス間通信の問題だ。」
Aさん「プロセス間通信?」
たろー「Worker Process の数が多いとプロセスの同期をとるため、プロセス間通信が多く発生する。それに加えて今回のトランザクションでは データベースリンク が存在するだろ?saki データベースでも多くのWorker Process が存在するから、おそらくプロセス間通信が ボトルネック になってしまっているんだ。」
Aさん「なるほど。だから Worker Process の数が少ない開発環境では再現しなかったのか・・・。」
たろー「全て憶測でしかないけど、結果を見る限りそうとしか思えない。 AWR や ASH を確認しても、 IO に ボトルネック は無かったしな。」
Aさん「ふむ、とりあえず問題解決だ!シフト勤務までした甲斐があったよ。
これでお客様に良い報告が出来る。付き合ってくれてありがとう、たろーちゃん!」
問題を解決した頃には、オフィスの外は明るくなり始めており、たろーちゃんとAさんは会社で日の出を迎えることになりました。
強敵 log file sync 問題を解決したたろーちゃんは、体はクタクタですが気持ちは達成感に満ちていました。
今回の「心臓外科医の術式」いかがだったでしょうか?
SQL チューニングと違い、log file sync での遅延はチューニングしづらい項目です。
COMMIT はトランザクションの区切りであり、LGWR は必ずこれを書き出さなければなりません。これは、DBMS が必ず保証しなければならない ACID 特性【 Atomicity Consistency Isolation Durability 】の1つ、Durability(耐久性/永続性)になります。
そこには必ず IO が発生するため、パフォーマンスチューニングを行う上で、どうしようもないジレンマに陥ることがあります。
しかし今回のように、IO 以外(同期処理等)に問題が起きていることもあるのです。
そんな log file sync の遅延を解決する、見事な「術式」だったのではないでしょうか?
次回も頑張りますので、応援よろしくお願い致します。
御客様へお願い・・・。以前の記事でもお伝えしたのですが、
ちゃんとした性能テストを行うには、本番環境と同等な構成の開発環境が必要です。
予算の御都合があるのは重々承知しておりますが、
その辺りも是非考慮に入れて頂けると幸いです。
投稿者プロフィール
-
「親しみやすさと技術力」をテーマに、技術情報・サービス・インフラ系資格取得に役立つ情報、社員等の情報をお届けします。
90名強の事業部員で鋭意、執筆中です。
少しでも当社を知って頂けるよう、愛情込めて頑張ります!
※facebook、X(旧twitter)、インスタグラムでは「DBひとりでできるもん」の更新情報を発信しています。
最新の投稿
 AIメディアブースト2025年12月11日チャットボット導入時の課題を解決!AIメディアブーストで手軽に高性能AIチャットボットを実装!
AIメディアブースト2025年12月11日チャットボット導入時の課題を解決!AIメディアブーストで手軽に高性能AIチャットボットを実装! AIメディアブースト2025年11月21日AIメディアブースト徹底ガイド|機能・サービスまとめリンク集
AIメディアブースト2025年11月21日AIメディアブースト徹底ガイド|機能・サービスまとめリンク集 AIメディアブースト2025年11月20日【撮影裏をご紹介】DBひとりでできるもん動画撮影会
AIメディアブースト2025年11月20日【撮影裏をご紹介】DBひとりでできるもん動画撮影会 AIメディアブースト2025年11月19日売上数十億円!!BtoB企業のオウンドメディア運営者が語る成功事例!
AIメディアブースト2025年11月19日売上数十億円!!BtoB企業のオウンドメディア運営者が語る成功事例!

