こんにちは、プラチナホルダー浜辺です。
最近、大規模システムで「 RMAN によるDBバックアップが遅い」
という相談が増えておりますので、
本記事にてDBバックアップ時間を短くするテクニックをご紹介します。
※注意※
本記事ではDBバックアップの取得方法として RMAN の利用を前提としております。
プラチナホルダー浜辺執筆&登場記事はこちらを参照ください!(一部紹介)

新年1発目の講演してきました!
PDBの作成方法
PDBの自動起動
DBバックアップが遅い原因は?
RMAN のDBバックアップですが、ざっくりと以下の流れで行われます。

一般的にDBバックアップに時間が掛かる要因としては、以下が考えられます。
[1. 読み込みフェーズ]
・DBファイルの配置先が低速なディスクである ・DBファイルの配置先のディスクにアクセスが集中している ・ネットワーク帯域が狭い(不足)
[ 2. コピーフェーズ ]
・CPUの性能が悪い ・CPUの負荷が高い
[ 3. 書き込みフェーズ ]
・DBバックアップの配置先が低速なディスクやテープである ・DBバックアップの配置先にアクセスが集中している ・ネットワーク帯域が狭い(不足)
上記以外にも、 RMAN の処理が原因で、ハードウェアの性能を活かしきれず
期待する性能を出せてないケースもありますね。
一般的なチューニング方法
バックアップが遅い場合には、
まずはハードウェア側でボトルネックが発生していないかを確認します。
Linux環境の場合は、 vmstat 、top 、iostat 、sar などのコマンドで
ハードウェアの負荷状況を確認できます。
ハードウェア側に問題がないようであれば、
ハードウェアの性能をフルに活かしきれていない可能性があるので、
RMAN で以下の設定変更を検討します。
- 処理の並列度(パラレル度)
- 圧縮(圧縮レベル)
幾つか、チューニング事例を紹介します。
ハードウェア調査結果:CPU負荷が高かった
圧縮を用いている場合には、非圧縮または圧縮レベルを下げてみることを検討する。
ハードウェア調査結果:読み込みに対して、書き込みが遅い
SSD等、高性能ディスクへの取得を検討してみる。 テープ装置に対してのバックアップを行っている場合は、一次バックアップをASMやローカル領域に取得し、 二次バックアップとしてテープ装置を活用することを検討する。
ハードウェア調査結果:問題なし
ハードウェアの性能をフルに活かしきれていない可能性があるので並列度を増やしてみる。
一般的なチューニング方法は、このような形かと思います。
思わぬ落とし穴…
ここからが本題です!!!
最近ご相談頂いた環境では、バックアップ処理の並列化や圧縮が利用されておりました。
さらなる高速化のために並列度を増やしたようですが効果がないとのことです。
ハードウェア調査結果も異常無しだそうです。
そういう環境では、以下を確認してみてください。
- データファイルのサイズに偏りがないか
- RMAN で「SECTION SIZE」を指定されているか
データファイルのサイズに偏りがあり、
「SECTION SIZE」が指定されていない場合は改善の余地ありです。
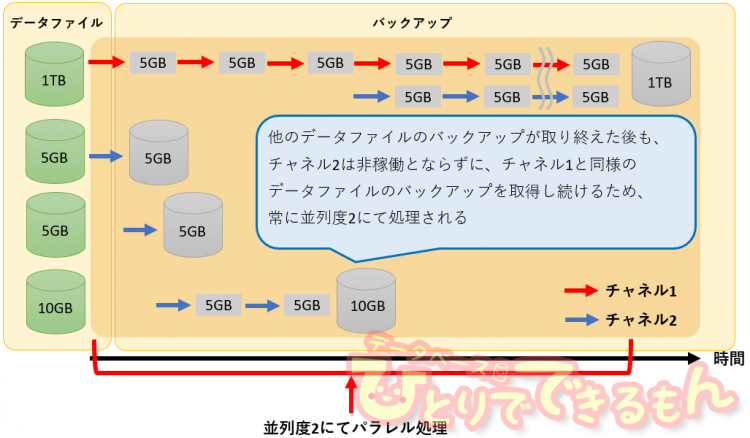
上記のような環境では下図のようなバックアップ処理となっている可能性があります。
この環境では、並列度2でバックアップが取得されることを期待してましたが、
残念ながら途中からシリアル処理となってます。
なぜこのような結果となってしまったのでしょうか。
通常、パラレルバックアップでは
バックアップ対象のデータファイル1つに対して1つのチャネルが割り当てられます。
つまり、並列処理の1つ1つの処理は、データファイル単位となります。
先ほどのように、1つのデータファイルだけが数TB持っており、
その他のデータファイルが数GBの場合、
最初は並列処理でバックアップが処理されますが、
暫くすると、バックアップを取得するデータファイルが無くなり
数TBのデータファイルのみがシリアルでバックアップされることになります。
この状況ではいくら並列度を上げても、バックアップ処理時間は改善されません。
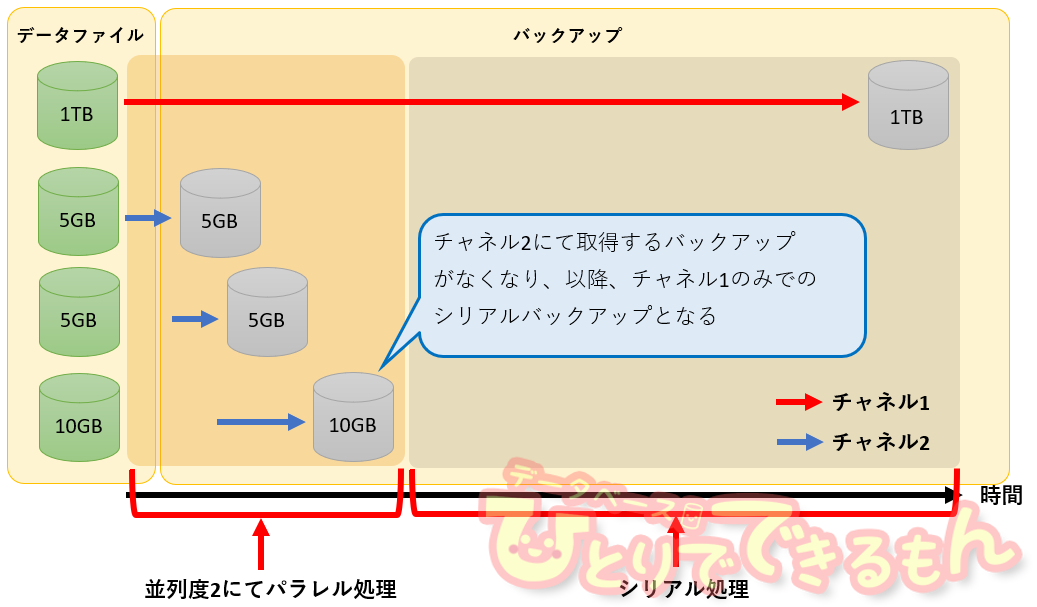
このような環境では、マルチセクション・バックアップを利用すると
速度を改善できます。
マルチセクション・バックアップはバックアップコマンドで
「SECTION SIZE」を指定することで機能します。
RMAN> backup incremental level 0 database;[マルチセクション・バックアップ]
RMAN> backup incremental level 0 database section size 5G;
マルチセクション・バックアップでは、データファイルのバックアップを
指定したサイズ単位に分割して処理することが可能ですので
数TBのデータファイルについてもパラレル処理が可能となり、
先ほどのバックアップは以下の図のようなに改善されます。
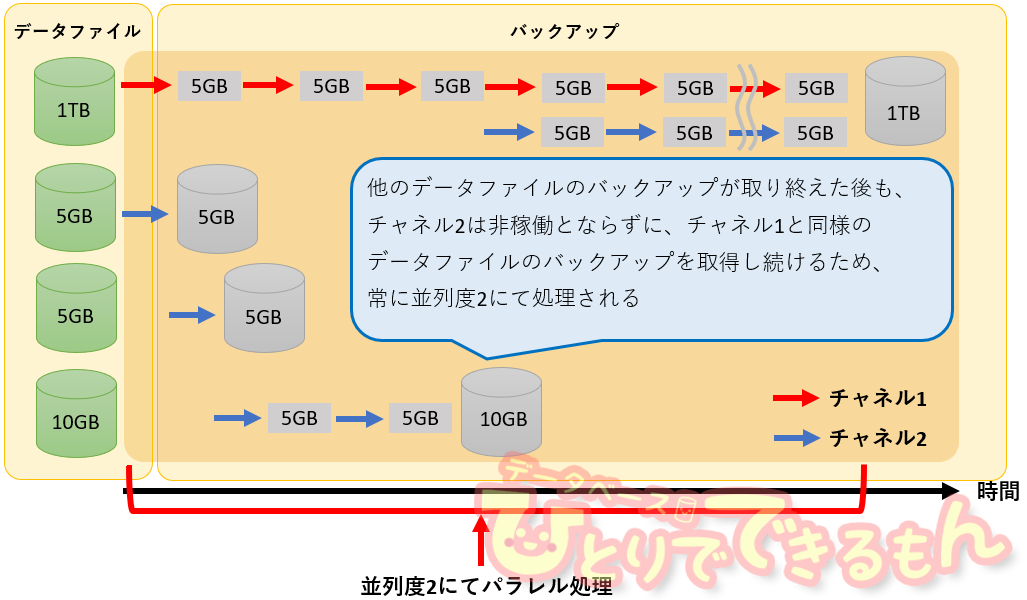
先日、相談頂いたお客様の環境もこのマルチセクション・バックアップの機能を取り入れて改善しました。
この機能を利用すると、もう一つメリットがあります!!!
それは、DBリストア時間の短縮です。
リストアについてもバックアップ同様、データファイル単位で処理が行われるため、
この機能を利用することで時短可能です。
RTOの要件が厳しいシステムは多いと思いますので
このメリットは非常に嬉しいですね!
なぜこのような問い合わせが増えてきたか?
ここ最近、bigfile表領域が採用されるシステムが増えてきてます。
この背景としては、DBに保管するデータ量が増え、
従来のsmallfile表領域ではデータファイル数が数十、数百~
と膨大な数が必要となり、管理が難しくなったからと考えております。
従来のsmallfile表領域であれば、データファイルのサイズは小さいため、
これまで通りの方法で、バックアップがうまく機能していたのですが、
bigfile表領域の利用により、
マルチセクション・バックアップを活用しないと
パラレル処理が働かないことによる処理遅延が発生しております。
なので、bigfileを採用する場合には、
是非マルチセクション・バックアップの採用を検討してください。
投稿者プロフィール



アナタにおすすめのこちらの関連記事も読んでみませんか?
 ORACLE MASTER Gold Oracle Database 12cを取得しました!
ORACLE MASTER Gold Oracle Database 12cを取得しました! 【再掲載】クラウド・ガードを設定してみました③~リスクへの対応の自動化~
【再掲載】クラウド・ガードを設定してみました③~リスクへの対応の自動化~ 【再掲載】便利機能!DBaaSモニター・コンソールの利用(2017年12月18日現在)
【再掲載】便利機能!DBaaSモニター・コンソールの利用(2017年12月18日現在) Oracle Cloud Infrastructure 2021 Certified Cloud Operations Associate / Oracle Cloud Infrastructure 2021 Certified Architect Associateを取得しました!
Oracle Cloud Infrastructure 2021 Certified Cloud Operations Associate / Oracle Cloud Infrastructure 2021 Certified Architect Associateを取得しました! 【再掲載】Terraformを利用してOCI環境を作成してみました
【再掲載】Terraformを利用してOCI環境を作成してみました 【再掲載】【Dbvisit Standby】最新バージョン(Ver.10.1.0)がリリースされます!
【再掲載】【Dbvisit Standby】最新バージョン(Ver.10.1.0)がリリースされます! 実は簡単!Oracleライセンスの見積もり方!(2018年4月19日現在)
実は簡単!Oracleライセンスの見積もり方!(2018年4月19日現在)